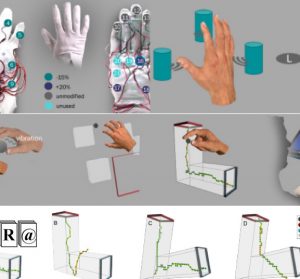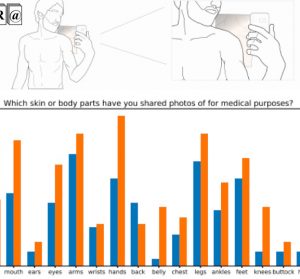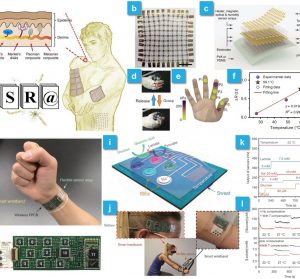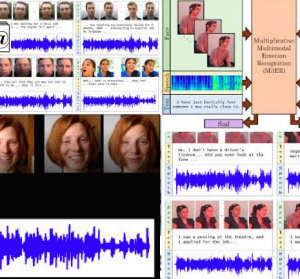
M3ER: Multiplicative Multimodal Emotion Recognition Using Facial, Textual, and Speech Cues
Abstract We present M3ER, a learning-based method for emotion recognition from multiple input modalities. Our approach combines cues from multiple co-occurring modalities (such as face, text, and speech) and also […]


![Coordination between control layer AI and on-board AI in optical transport networks [Invited]](https://ksra.fr/wp-content/uploads/2020/08/Artificial-Superintelligence-In-Control-300x279.jpg)